Mastering the Power of MapReduce in Java: A Comprehensive Guide
Related Articles: Mastering the Power of MapReduce in Java: A Comprehensive Guide
Introduction
With enthusiasm, let’s navigate through the intriguing topic related to Mastering the Power of MapReduce in Java: A Comprehensive Guide. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
- 1 Related Articles: Mastering the Power of MapReduce in Java: A Comprehensive Guide
- 2 Introduction
- 3 Mastering the Power of MapReduce in Java: A Comprehensive Guide
- 3.1 Understanding the Essence of MapReduce
- 3.2 Diving into the Implementation: A Java Perspective
- 3.3 The Power of MapReduce: Unleashing its Potential
- 3.4 Real-World Applications: Transforming Industries
- 3.5 Frequently Asked Questions: Addressing Common Concerns
- 3.6 Tips for Effective MapReduce Development
- 3.7 Conclusion: A Powerful Tool for Big Data Processing
- 4 Closure
Mastering the Power of MapReduce in Java: A Comprehensive Guide
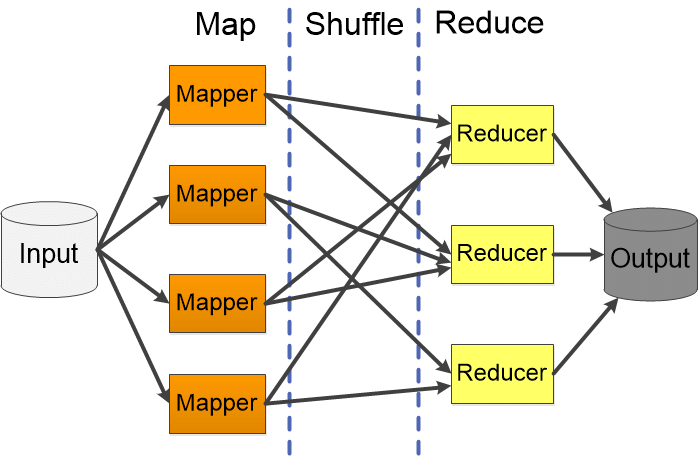
In the realm of big data processing, the ability to efficiently handle massive datasets is paramount. Enter MapReduce, a programming model that revolutionized the way we process vast amounts of information. This guide dives deep into the intricacies of MapReduce in Java, illuminating its core principles, implementation, and real-world applications.
Understanding the Essence of MapReduce
At its core, MapReduce is a distributed computing paradigm that empowers parallel processing across multiple nodes. It breaks down complex tasks into two fundamental phases:
- Map: This phase takes the input data and transforms it into key-value pairs. Imagine it as a process of sorting and organizing raw information.
- Reduce: This phase aggregates the key-value pairs generated by the Map phase, performing operations like summation, averaging, or counting. Think of it as consolidating the organized data into meaningful insights.
This two-step approach enables MapReduce to handle large datasets efficiently by distributing the workload across multiple machines.
Diving into the Implementation: A Java Perspective
Java, with its robust libraries and mature ecosystem, provides an excellent platform for implementing MapReduce solutions. The Hadoop framework, a widely adopted implementation of MapReduce, offers a powerful set of tools for developers.
1. The Hadoop Ecosystem
Hadoop is a cornerstone of MapReduce in Java, comprising three core components:
- Hadoop Distributed File System (HDFS): This distributed file system stores the massive datasets that MapReduce processes, ensuring high availability and fault tolerance.
- YARN (Yet Another Resource Negotiator): YARN manages the resources required for MapReduce jobs, allocating computational resources to individual tasks.
- MapReduce Framework: This framework provides the core logic for executing MapReduce jobs, handling data partitioning, shuffling, and the execution of Map and Reduce tasks.
2. The Anatomy of a MapReduce Job
A typical MapReduce job in Java involves the following steps:
- Defining Input and Output Formats: Specify the format of the input data (e.g., text files, CSV files) and the desired format of the output (e.g., text files, JSON files).
-
Implementing the Mapper Class: The Mapper class takes input data and transforms it into key-value pairs. This class defines the
map()method, which performs the transformation logic. -
Implementing the Reducer Class: The Reducer class aggregates the key-value pairs generated by the Mapper class, performing operations based on the specific task. This class defines the
reduce()method, which handles the aggregation logic. - Configuring the Job: Specify the input and output paths, the number of mappers and reducers, and other configuration parameters for the job.
- Submitting the Job: Submit the configured job to the Hadoop cluster for execution.
3. Example: Word Count in Java
Let’s illustrate the concept with a simple example: counting the occurrences of words in a text file.
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
for (String token : value.toString().split("s+"))
word.set(token);
context.write(word, one);
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable>
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException
int sum = 0;
for (IntWritable val : values)
sum += val.get();
result.set(sum);
context.write(key, result);
public static void main(String[] args) throws Exception
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
This code snippet defines a Mapper class that splits the input text into words and emits each word as a key with a value of 1. The Reducer class then aggregates the counts for each word, producing the final word count.
The Power of MapReduce: Unleashing its Potential
MapReduce, when implemented effectively, offers numerous advantages:
- Scalability: MapReduce excels at handling massive datasets by distributing the processing workload across multiple nodes. This scalability ensures efficient processing even for petabytes of data.
- Fault Tolerance: The distributed nature of MapReduce provides inherent fault tolerance. If a node fails, the system can automatically re-assign tasks to other available nodes, ensuring uninterrupted processing.
- Simplicity: The MapReduce paradigm simplifies the development process by breaking complex tasks into manageable Map and Reduce phases. This modularity promotes code reusability and maintainability.
- Parallelism: MapReduce leverages the power of parallel processing, significantly reducing the time required for data analysis and processing. This parallelism translates to faster insights and quicker decision-making.
Real-World Applications: Transforming Industries
MapReduce’s power extends beyond simple word counting. It finds widespread applications in various domains, including:
- Web Analytics: Analyzing website traffic patterns, user behavior, and clickstream data to understand user engagement and optimize website performance.
- Social Media Analysis: Extracting insights from social media data, identifying trends, sentiment analysis, and understanding public opinion.
- Scientific Computing: Processing large datasets generated by scientific simulations, analyzing genomic data, and performing complex calculations in fields like astrophysics.
- E-commerce: Personalizing recommendations, analyzing customer behavior, and optimizing pricing strategies based on massive transaction data.
Frequently Asked Questions: Addressing Common Concerns
1. What are the limitations of MapReduce?
While powerful, MapReduce has limitations:
- Data Locality: Data movement can be a performance bottleneck, especially when data is not evenly distributed across the cluster.
- Complex Data Structures: MapReduce is primarily designed for processing key-value pairs, making it less suitable for handling complex data structures.
- Iterative Processing: MapReduce is not ideal for iterative algorithms that require multiple passes over the data.
2. What are the alternatives to MapReduce?
Several alternatives have emerged, addressing some of the limitations of MapReduce:
- Spark: A faster and more versatile framework that supports both batch and real-time processing.
- Flink: A framework designed for real-time data processing and stream processing.
- Hadoop YARN: While not a direct replacement, YARN provides a platform for running various frameworks, including Spark and Flink, alongside MapReduce.
3. How do I choose the right framework for my needs?
The choice of framework depends on the specific requirements of the task:
- For batch processing of large datasets: MapReduce or Spark are suitable choices.
- For real-time data processing: Flink is a better option.
- For iterative processing: Spark’s iterative capabilities make it a suitable choice.
Tips for Effective MapReduce Development
- Optimize Data Partitioning: Ensure data is evenly distributed across nodes for efficient parallel processing.
- Use Combiners: Reduce the amount of data transferred between mappers and reducers by using combiners to perform partial aggregation.
- Choose Appropriate Data Types: Select data types that optimize storage and processing efficiency.
- Implement Custom Partitioners: Control how data is partitioned for efficient processing based on specific requirements.
- Leverage Hadoop’s Debugging Tools: Utilize Hadoop’s debugging tools to identify and resolve performance bottlenecks.
Conclusion: A Powerful Tool for Big Data Processing
MapReduce, with its simplicity, scalability, and fault tolerance, has transformed how we process and analyze large datasets. Its versatility makes it applicable across diverse domains, empowering organizations to extract valuable insights from vast amounts of data. While newer frameworks like Spark and Flink have emerged, MapReduce remains a powerful tool for handling batch processing tasks and continues to play a significant role in the big data landscape. By understanding the core principles and implementation details of MapReduce in Java, developers can unlock its potential and leverage its capabilities to address complex data processing challenges.


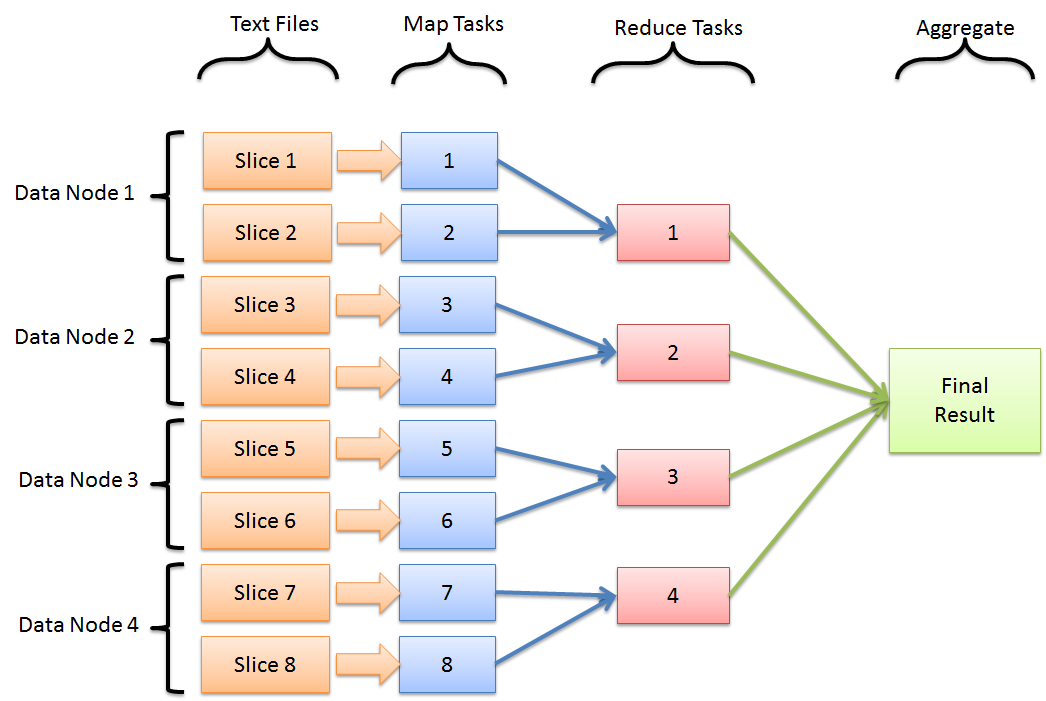





Closure
Thus, we hope this article has provided valuable insights into Mastering the Power of MapReduce in Java: A Comprehensive Guide. We thank you for taking the time to read this article. See you in our next article!